
Some time ago I started the TestOps series. I outlined why the topic is important (actually I expect it to be even more important in the nearest future) and listed various topic which I'd like to investigate deeper soon. Today the first from the list: Testing in Production.
I'll list prerequisites for successful TiP adoption and give you real-life examples from top companies. Let's begin with a definition though:
Testing in Production (TiP) is a set of software testing methodologies that utilises real users and production environment in a way that both leverages the diversity of production, while mitigating risks to end users.
Prerequisites
Mature engineering process
Testing in production impacts your application running live, therefore it impacts your customers. You should always have this statement on the back of your head. There is no place for dummy data like $99,999.00 little mouse (funny example from Amazon below).
Before you approach it you need to make sure you fully understand its impacts. You should have skilled people planning and executing it from start to finish. Usually when it comes to testing error margin is quite big, but that's not the case in TiP.
Understanding and mitigating risks
In the social media era once you show something on the Internet it stays there forever. However, there are also risks that are not so obvious. Be careful especially with performance/load tests. Even the slightest decrease in application speed may substantially impact revenue & conversion.
What about your monitoring & alerting? Would your tests trigger any false positives alarms? Do you even have possibilities to check how your tests impact performance metrics?
Have you thought about the data you collect? Once you generate fake traffic it may be corrupted. How can you then make data-driven decisions?
Cleaning after yourself
This is something you should have implemented in the testing environment too, but which is a must on production. Your tests may generate all kinds of useless stuff - users, database entries, fake data, logs. Make sure you erase them afterward. In case of logs add something to quickly identify a test. You don't want to spend time analyzing non-human traffic.
Types of TiP
Canary deployment & Blue-Green deployment
You deploy your software on a separate set of servers (Blue pool in the image below) and then slowly roll it out for customers. Start small (with internal or beta users) and do few smoke tests and log analyses. If everything seems ok redirect some part of external customers (5% in our example) for the new pool.
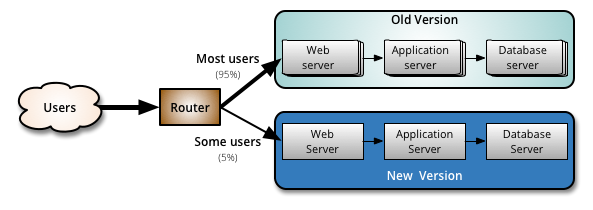
Now assuming if something goes wrong you may rollback all traffic to sta able pool (Green) or just proceed with new release rollout and redirect half/all customers to Blue pool.
In case of a new software version you revert the roles, deployment is now on Green pool with Blue pool running as a safety net in case of unexpected bugs.
The goal here is to make the process transparent for customers.
On Martin Fowler's blog, you can find a more detailed and excellent description of those techniques: Canary release, Blue-Green deployment.
Controlled test flight
The technique very similar to Canary deployment, but instead of a new application version we slowly roll out new features. I'll use Aviadezra image to explain it in a simple way:
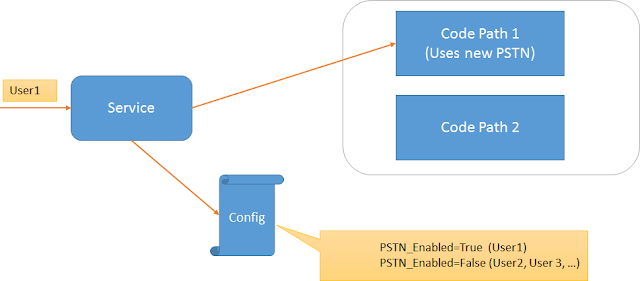
Let's assume we have a new feature hidden in Code Path 1. After successful deployment, we have all customers using Code Path 2. Now we change the config file and from now on some customers (first internal, then 5%) are using a new feature that is visible in Code Path 1.
Once again we analyze how the application is performing, and if everything is ok we open Code Path 1 for all customers. If we are disappointed by the results we rollback to Code Path 2.
The warning here: controlled test flight substantially increase application complexity. Business loves it though and in my opinion, it's worth the effort.
A/B testing
Another excellent tool for business and UX designers. I'll use a vwo image for an explanation (excellent guide, read it).
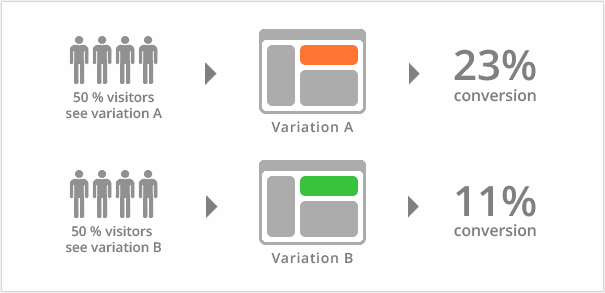
The idea is very simple here. 50% of our customers see Variation A of our application, and 50% of customers see Variation B. We measure all the data and then analyze it (with Data Scientists help perhaps). In the case of our example, Variation A is better because it guarantees a higher conversion rate.
A/B testing is highly recommended by lean experts and you should utilize it even in startups.
Synthetic User (Bot) Testing
Synthetic user is a bot which runs real customer scenario on our application. To be more specific it's like an end-to-end (E2E) test running on a production environment. Tests don't have to be written using Selenium (as they're very often unstable) but should run popular journeys. Ideally, you should figure out scenarios using production data.
Bots may be triggered from various servers (ideally split geographically) and should be integrated with existing monitoring/alerting systems. Consecutive failures should trigger an investigation in your team.
Make sure you clean your data after each run (see prerequisite 3).
Fault injection & Recovery testing
Technique popularised by Netflix's Chaos Monkey. The idea is pretty simple - we generate random failures in our production infrastructure enforcing engineers to design recovery systems and develop a stronger, more adaptive platform.
The best defense against major unexpected failures is to fail often. By frequently causing failures, we force our services to be built in a way that is more resilient
Cory Bennett and Ariel Tseitlin - Netflix engineers
Dogfooding
Technique popularised by Microsoft which enforces usage of applications developed locally. For example, if your team is creating new GoogleDocs you force your developers to use it. A very clever way to improve the customer user experience.
Comments
Loading comments...