

Playwright MCP is the latest big thing in the test automation world. It connects one of the most popular testing tools, Playwright, with the emerging AI trend known as Model Context Protocol (MCP). The result? A powerful new way to bring AI agents into the software testing space.
With Playwright MCP, AI agents within modern IDEs or using CLI can understand and interact with the browser like a real user, generate tests, and even help uncover bugs. It’s a whole new way to think about what automation can do.
In this post, I’ll walk through what Playwright MCP is, how it works, and why it could be a game-changer for the future of testing.
Theory
Before we dive into the technical details, it’s worth taking a step back and looking at the bigger picture.
Playwright MCP opens up powerful new capabilities — but to really get the most out of it, we need to understand why it works the way it does. This isn't just another test automation tool you can plug in and go. It’s built on top of modern AI concepts like LLM function calling and a new open standard called the Model Context Protocol (MCP).
So in the next sections, we’ll lay the groundwork. I’ll give a quick refresher on how today’s AI models interact with tools, and then show how MCP turns that into a universal language for AI agents.
LLM Function Calling
To understand how AI agents can do meaningful tasks — like running commands, searching files, or interacting with your system — we first need to look at how LLM function calling works behind the scenes.
Modern language models (like GPT-4.1) aren’t just text generators anymore. They can also call functions (tools in API definition) — but only if those functions are explicitly defined and exposed by developers. On image above you can see tools provided by OpenAI available for GPT-4.1.
The Function Calling Workflow
Let’s walk through what’s actually happening step by step.
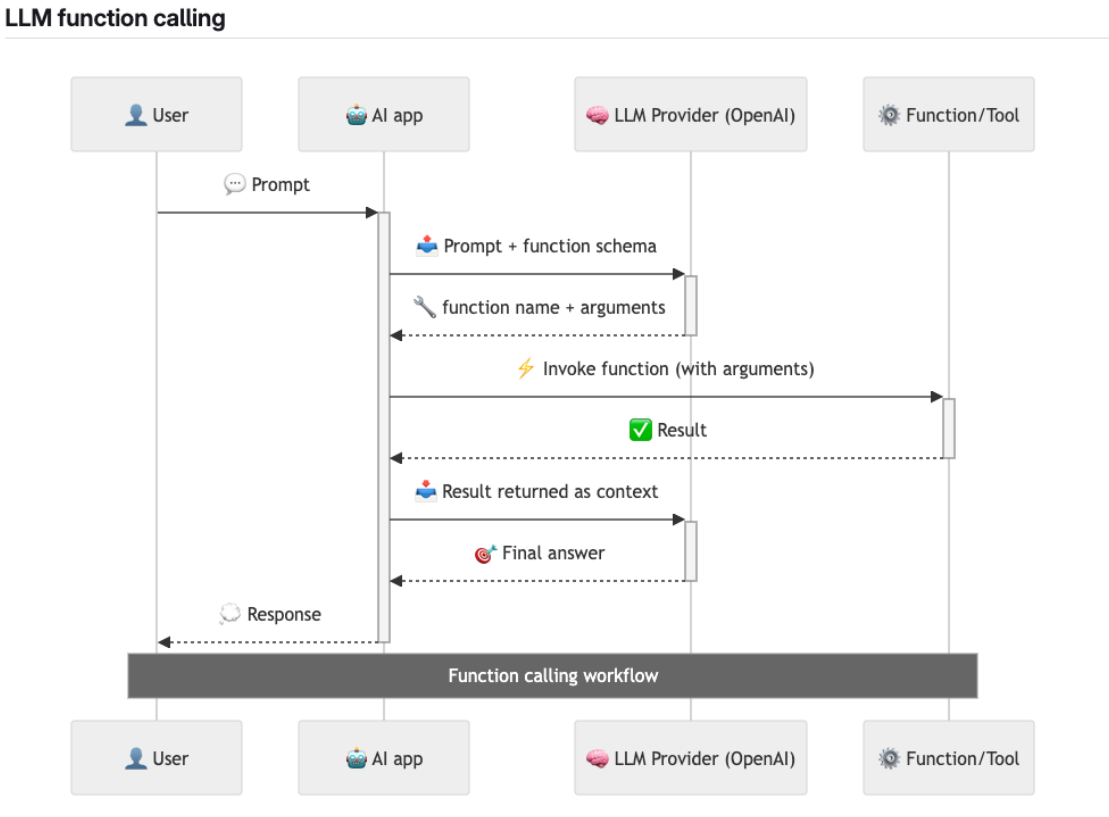
-
The user prompts the AI, e.g. “Show me all files modified today.”
-
The AI app passes that prompt to an LLM provider (like OpenAI), along with a list of available tools and their schemas.
-
The model decides a tool needs to be used and returns a structured function call (function name + arguments).
-
The app executes the tool and gets a result (e.g., list of files).
-
That result is fed back to the model, which produces a final answer for the user or calls another tool.
Alternatively, you can analyse the following flowchart:
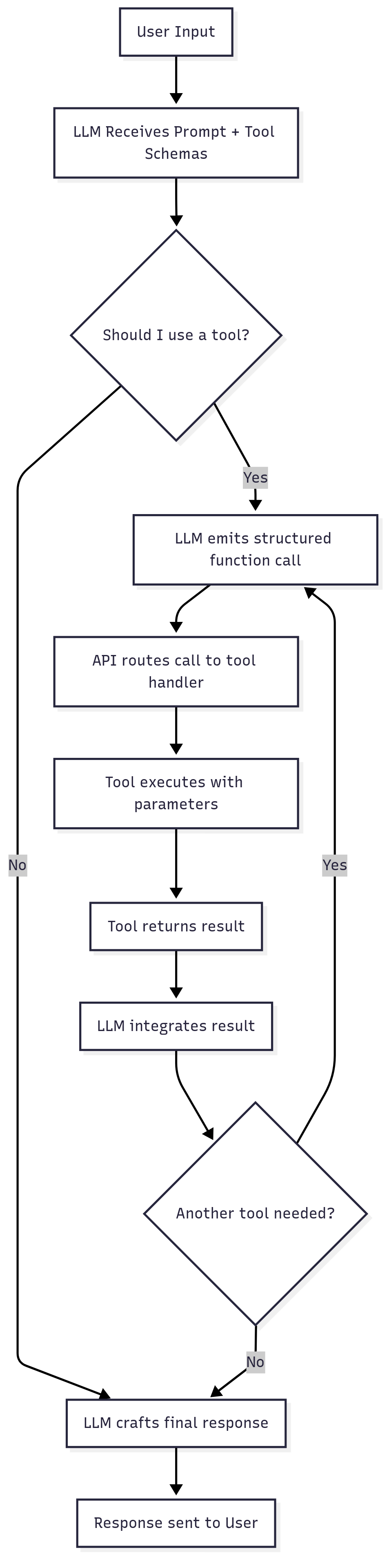
The key takeaway here: the AI doesn’t have free rein — it can only call tools that were registered ahead of time, using a strict schema.
Tools Are Hardcoded (and Maintained) by AI Apps Developers
Unlike plugins you might install dynamically, tools for function calling are hardcoded into the agent’s environment by its developers. Each tool includes a schema that defines what the AI is allowed to call, what arguments are expected, and how the output should be interpreted.
Let’s take a real example from the Cursor IDE, an AI-powered code editor developed by Anysphere. Cursor exposes a tool called run_terminal_cmd, which allows the AI to suggest terminal commands — but requires user approval before anything is executed.
Here's the tool definition (excerpted for clarity):
{
"name": "run_terminal_cmd",
"parameters": {
"required": ["command", "is_background", "require_user_approval"],
"properties": {
"command": { "type": "string" },
"explanation": { "type": "string" },
"is_background": { "type": "boolean" },
"require_user_approval": { "type": "boolean" }
}
},
"description": "Propose a command to run on behalf of the user. Requires approval."
}
When the user types a request, the agent determines whether it can satisfy it using one of its tools — and if so, it returns a proposed command, like:
{
"command": "git status",
"is_background": false,
"require_user_approval": true,
"explanation": "Check for uncommitted changes before running build."
}
Once approved, the command is executed, and the result is routed back to the LLM, which then uses that new context to decide what to do next — whether that’s explaining the output, suggesting a follow-up command, or summarizing the result. Note that the tools are executed on client side, not on the server side.
Model Context Protocol (MCP)
Now that we understand how LLM function calling works — using pre-defined tools hardcoded by developers — the next logical question is:
How do we expand that toolbox without constantly patching the AI app itself?
That’s exactly what Model Context Protocol (MCP) was designed for.
MCP servers as a LLM Function Calling extension
LLMs like GPT-4.1 don’t automatically “know” how to click a button, read a file, or drive a browser. They can only call tools that have been explicitly registered in their environment.
Typically, those tools are embedded directly into the AI app — for example, in Cursor, where the tools are defined and maintained by the Cursor team at Anysphere.
With MCP, we get a much more flexible alternative. AI apps can dynamically connect to external MCP servers, which expose entire sets of callable tools.
These servers act as extensions. You don’t need to modify the AI app itself — you just connect it to an MCP-compliant server, and the app discovers the available tools using a standard handshake defined in the MCP specification.
MCP flow
Let’s break down what’s really happening when an AI uses a tool provided by an MCP server — using Cursor as an example MCP client, and Playwright MCP as the connected server.
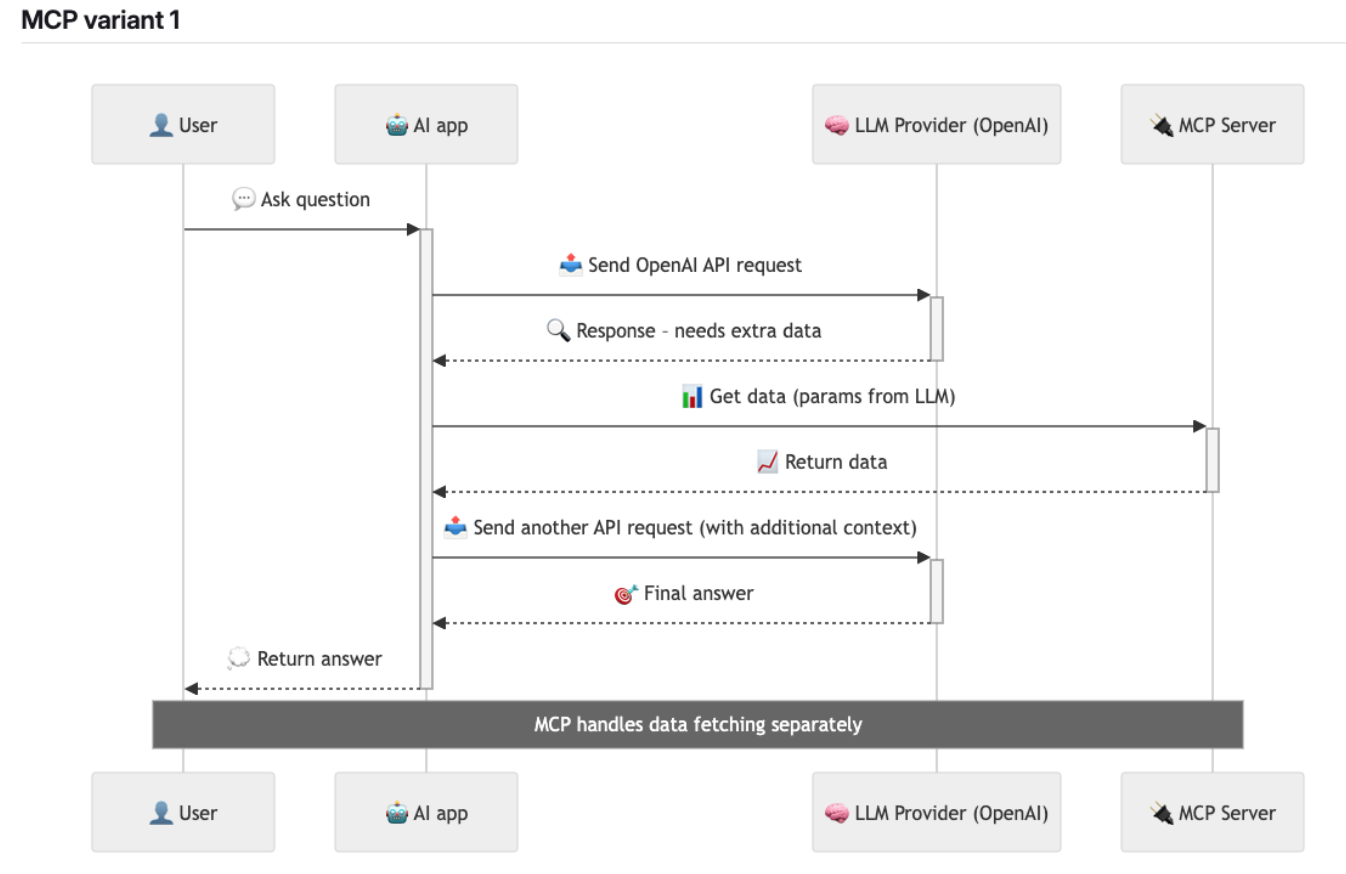
-
The user connects to an MCP server via an MCP client (e.g. Cursor or VS Code).
-
The MCP client performs a handshake to discover the tools available on the MCP server.
For example, the Playwright MCP server might expose tools like
browser_navigate,browser_click, andbrowser_snapshot. -
The user types a natural-language prompt, such as:
“Test the login flow in my app.”
-
The AI app sends this prompt to the LLM provider (e.g. OpenAI), including the tool definitions it has — both built-in and those discovered from the connected MCP server.
-
The LLM evaluates the request and selects one of the available tools — for example, it might decide to use
browser_navigate. -
The LLM returns a function call to the MCP client, instructing it to invoke that specific tool with the right parameters.
-
The MCP client calls the selected tool on the MCP server.
In this case, Playwright MCP might launch a browser, navigate to the specified URL, and return a structured result.
-
The result is returned to the LLM, which updates its context and decides what to do next — possibly calling more tools.
-
This loop continues until the LLM produces a final answer, which is returned to the user.
The key distinction here: instead of building every possible tool into the AI app upfront, MCP handles tool access dynamically, through standard interfaces.
Key takeaways
With MCP, you don’t need to build every possible integration directly into the AI app.
Instead, MCP handles tool access dynamically, using a standardized, pluggable interface. This means the AI can call tools hosted on any compliant server — without the AI app needing to know implementation details ahead of time.
This unlocks powerful flexibility:
- You can extend the AI’s capabilities just by connecting to a new MCP server.
- These servers can expose tools for browser automation, file access, databases, Git operations, and more.
- And in corporate or team-based environments, this separation of concerns is a huge win:
- Team A can build and maintain the MCP server (tool logic)
- Team B can maintain the AI app (prompting, orchestration, UI)
- Both evolve independently — without tight coupling or redeployment loops.
MCP essentially turns tools into API-like services that any AI agent can discover and use, enabling modular, scalable, and maintainable AI-integrated systems.
Playwright MCP
Playwright MCP is an MCP-compliant server that wraps the capabilities of the Microsoft Playwright browser automation framework and exposes them to AI agents as callable tools. Once connected, it gives the AI safe (at least in theory), structured control over a real browser — using nothing more than high-level, semantic instructions.
The simplest setup inside a MCP client (e.g. Cursor) looks like this:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}
Tools
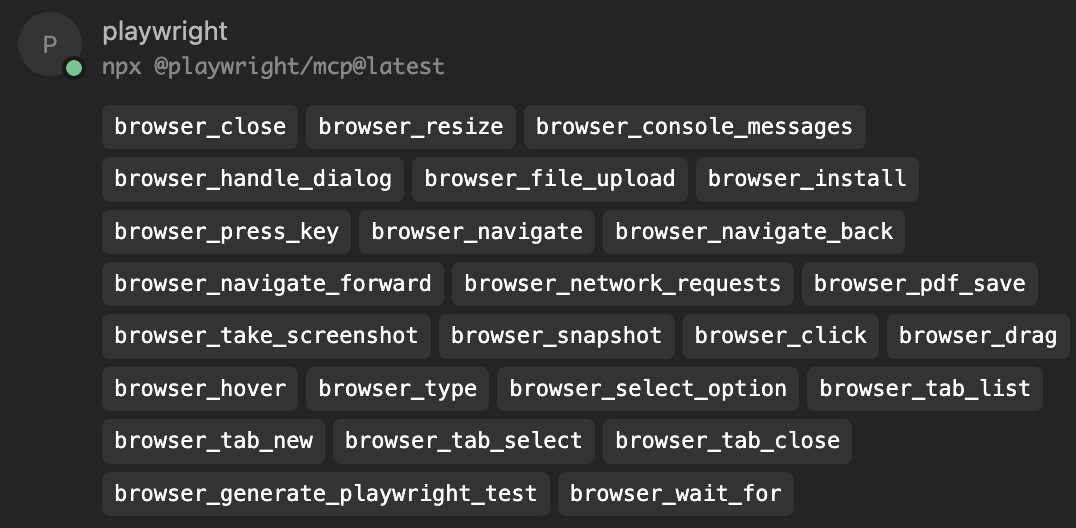
Once connected, the AI gains access to a wide range of browser automation tools, grouped by function:
| Group | Tool | Description |
|---|---|---|
| 🧭 Navigation | browser_navigate | Navigate to a specified URL |
browser_navigate_back | Go back to the previous page | |
browser_navigate_forward | Go forward to the next page | |
| 🖱️ Interactions | browser_click | Click on a UI element (by role or label) |
browser_type | Type text into an input field, with optional submit or slow typing | |
browser_select_option | Select option(s) from a dropdown | |
browser_drag | Drag from one element to another | |
browser_hover | Hover the mouse over an element | |
browser_press_key | Press a specific key (e.g., Enter, ArrowLeft) | |
browser_file_upload | Upload one or more local files | |
browser_handle_dialog | Accept/dismiss a dialog or enter prompt text | |
| 👀 State & Observation | browser_snapshot | Get an accessibility tree snapshot of the current page (semantic UI representation) |
browser_wait_for | Wait for text to appear/disappear, or delay for a specific time | |
browser_network_requests | List all network requests made since page load | |
browser_console_messages | Retrieve all console messages from the browser | |
| 🧪 Testing Support | browser_generate_playwright_test | Generate a Playwright test script based on described steps |
browser_take_screenshot | Capture a JPEG/PNG screenshot of the page or specific element | |
browser_pdf_save | Save the current page as a PDF document | |
| 🖼️ Vision Mode (Fallback) | browser_screen_capture | Capture a full screenshot for visual analysis |
browser_screen_click | Click at specific screen coordinates | |
browser_screen_drag | Drag between screen coordinates | |
browser_screen_type | Type text at the screen level (no semantic context) | |
browser_screen_move_mouse | Move mouse to a coordinate without clicking | |
| 🗂️ Tabs & Window Management | browser_tab_list | List open tabs |
browser_tab_new | Open a new tab (optionally with a URL) | |
browser_tab_select | Switch to a tab by index | |
browser_tab_close | Close a tab (current or by index) | |
browser_resize | Resize the browser window to specific dimensions | |
browser_close | Close the current page or browser session | |
| ⚙️ Utilities | browser_install | Install the configured browser (e.g., if missing in CI) |
Please note that the tools are maintained by the Microsoft and by the time you read this, the list of tools might be different.
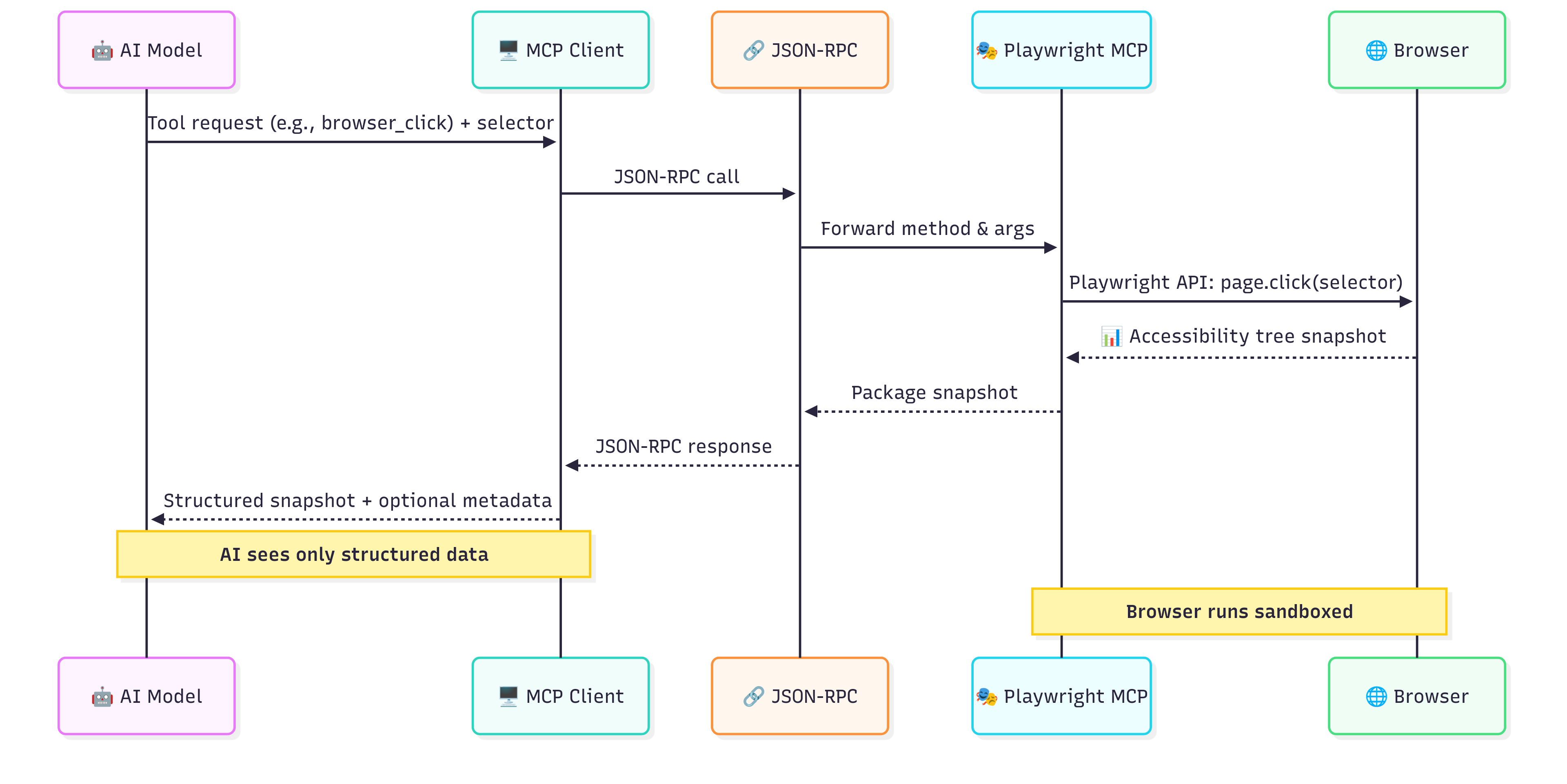
Architecture
At a high level, the flow works like this:
-
The LLM (e.g., GPT-4.1) decides it wants to perform an action, like clicking a button. It sends a tool request (e.g.,
browser_click) along with parameters (like a selector or element reference) to the MCP client. -
The MCP client (e.g., Cursor) wraps the request and sends it to the Playwright MCP server via a JSON-RPC call.
-
The Playwright MCP server receives the method and arguments, then uses the Playwright API to execute the action on a real browser instance.
-
The browser performs the action safely in a sandboxed environment. Once the action is complete, the server captures the resulting state — often in the form of an accessibility tree snapshot (semantic UI representation).
-
The snapshot (structured data + optional metadata) is passed back to the MCP client, then returned to the AI model.
Accessibility Tree
Earlier, we saw that Playwright MCP doesn't return raw HTML or screenshots as feedback from the browser. Instead, it gives the AI something far more structured and meaningful: an Accessibility Tree snapshot.
But this idea didn’t start with AI.
♿ Accessibility for Humans
The Accessibility Tree was originally created to help people with disabilities interact with the web.
Screen readers, braille displays, voice control systems — they all rely on a consistent, structured representation of the page's content and interactive elements. The raw HTML isn’t helpful on its own. What matters is:
- What can I click?
- What is this button labeled?
- Is this input field focused or disabled?
- What’s the structure of the page?
The browser takes the DOM and generates a semantic abstraction — the Accessibility Tree — which gives assistive technologies the right information to present, speak, or navigate the UI meaningfully.
What is Accessibility Tree?
The Accessibility Tree is a simplified, structured abstraction of the UI elements currently rendered on a page. It’s generated by the browser and describes:
- Elements’ roles (e.g., button, textbox, heading)
- Their names/labels (e.g., "Submit", "Email")
- Their states (e.g., focused, checked, disabled)
- Hierarchical structure (e.g., a button inside a form)
Think of it as the UI’s semantic skeleton — stripped of layout, styles, or irrelevant markup. It’s what matters when you’re trying to understand what a page means, not just how it looks.
Why Is This Ideal for AI?
Because LLMs don’t have spatial or pixel-level perception. What they can reason about is:
- “There is a button labeled Log In”
- “There is a textbox with placeholder Search”
- “A checkbox is currently checked”
This is exactly the kind of data the accessibility tree provides. It's stable, human-relevant, and structured — a perfect match for language models.
This is what Playwright MCP sends back to the AI after actions like browser_snapshot, browser_click, or browser_type.
Worth to add that Playwright officially recommends using user-facing attributes to XPath or CSS selectors like these:
page.getByRole('button', { name: 'submit' });
DOM vs. accessibility tree—hands-on example
Let’s look at a simple form in HTML and see how it translates into the Accessibility Tree:
<form>
<label for="email">Email</label>
<input id="email" type="email" required />
<button>Sign in</button>
</form>
Playwright code:
const tree = await page.accessibility.snapshot();
console.log(tree);
Sample output (abridged):
{
"role": "form",
"name": "",
"children": [
{ "role": "textbox", "name": "Email", "required": true },
{ "role": "button", "name": "Sign in" }
]
}
Note how the unlabeled <form> still gets a form role while the <input> inherits its name from the <label>—a direct result of the accname algorithm.
Use cases
Now that we’ve unpacked how Playwright MCP works, let’s look at what you can actually do with it. These are real, practical workflows that can improve your testing.
Functional Testing
Playwright MCP enables AI-driven functional tests where the agent behaves like a real user: it navigates, clicks, types, and validates what it sees — all using semantic cues from the accessibility tree rather than brittle DOM selectors.
You can direct the agent to verify login workflows, form submissions, error handling, or multi-step interactions like onboarding flows. The resulting tests are readable, resilient, and feel closer to how a human would actually interact with the app.
But here’s where it gets even more powerful: once your test cases are defined, the AI agent can run through the entire regression suite — without ever getting bored or distracted. It doesn’t just execute tests; it can also help maintain them:
- Create new tests on the fly when encountering untested flows
- Update test steps when the UI changes
- Add relevant assertions based on new features
- Remove obsolete steps from outdated tests
It’s like having a test assistant that’s always available, never fatigues, and is deeply familiar with the app’s current state. One prompt, and it’s ready to help — whether that means running a suite, fixing flaky cases, or generating new tests from scratch.
Exploratory Testing
You can prompt an AI to “explore the app and report anything strange,” and it will navigate, interact, and observe. It might even uncover bugs you didn’t think to test — like unexpected error messages, missing elements, or slow-loading pages.
As shown in real-world demos, agents have already caught regressions that humans missed.
Even better: you don’t have to be hands-on while it happens. If you’re pressed for time or juggling multiple tasks, you can simply launch an exploratory session and let the AI run its course in the background. While you review pull requests or write documentation, your AI copilot is busy clicking through flows, taking snapshots, and logging its findings.
It’s a practical way to make exploratory testing parallel, continuous, and less dependent on manual bandwidth — without sacrificing coverage.
Accessibility Testing
Since Playwright MCP operates through the accessibility tree, it naturally encourages accessible design. You can prompt the agent to:
- List unlabeled buttons or form fields
- Check heading levels for logical order
- Detect duplicate ids
- Report images with missing alt text
It’s not a replacement for dedicated tools like Axe or Lighthouse — but for quick audits or catching low-hanging fruit, it’s incredibly effective.
Tip: You can connect to an MCP server that integrates Axe for full audits — or just use the AI’s reasoning on snapshot data for instant insights.
Test Automation
Playwright MCP enables a new level of test automation by giving AI agents structured, semantic access to the live browser — no more guessing, no more workarounds.
In the past, if you wanted an AI to help debug or write a test, you often had to copy-paste DOM snippets, frontend code, or stack traces just to give it enough context. You might've asked it to "figure out what went wrong" based on a vague error message — which often led to hallucinated suggestions or generic advice.
With Playwright MCP, that friction is gone. The AI doesn’t have to imagine what your app looks like — it can see the actual website through the accessibility snapshot. It understands the UI like a screen reader would: with meaningful roles, labels, and states. That makes debugging, validation, and interaction vastly more accurate.
And here’s a key insight: AI agents operate in loops. They take actions, wait for results, and then decide what to do next — just like a human tester. But to function effectively, they need reliable feedback from the environment. That’s exactly what Playwright MCP provides: direct, structured feedback from the browser itself. After each interaction (click, type, navigate), the agent receives a fresh snapshot or diff — giving it immediate awareness of what changed and why.
There’s even a dedicated MCP tool for test generation:
browser_generate_playwright_test
With it, you can:
- Let the agent execute a functional test (via natural-language prompt or a scripted plan)
- Automatically generate a Playwright test script based on the actions it performed
- Review or tweak the output, then commit it to your suite like any other test
It’s automation for automation — and it changes how fast and flexibly we can build and maintain test coverage.
Debbie O'Brien recommends the following prompt for generating boilerplate Playwright test scripts:
- You are a playwright test generator.
- You are given a scenario and you need to generate a playwright test for it.
- DO NOT generate test code based on the scenario alone.
- DO run steps one by one using the tools provided by the Playwright MCP.
- When asked to explore a website:
1. Navigate to the specified URL
2. Explore 1 key functionality of the site and when finished close the browser.
3. Implement a Playwright TypeScript test that uses @playwright/test based on message history using Playwright's best practices including role based locators, auto retrying assertions and with no added timeouts unless necessary as Playwright has built in retries and autowaiting if the correct locators and assertions are used.
- Save generated test file in the tests directory
- Execute the test file and iterate until the test passes
- Include appropriate assertions to verify the expected behavior
- Structure tests properly with descriptive test titles and comments
Pro tip: For flaky legacy suites with CSS/XPath selectors, use MCP to generate modern equivalents.
Generating Documentation & Onboarding Materials
Playwright MCP doesn’t just power test automation — it can help generate living documentation by interacting with your application and turning those flows into human-readable content.
Because AI agents connected via MCP understand what’s happening in the UI — semantically, not just structurally — they can observe key user flows and generate clear, contextual explanations of:
- How to use features (“To upload a file, click the button labeled ‘Upload’, then select a file…”)
- Project setup steps (“First, open the login page, then enter your credentials. After logging in, you'll see the dashboard.”)
- Onboarding tutorials (“Here’s how to invite a team member to your workspace…”)
- Technical walkthroughs (“This is the flow the user goes through during checkout, with 5 main UI interactions and 3 API calls.”)
You can even guide the agent with prompts like:
Walk through the report generation flow, take screenshots, and produce a markdown document explaining each step
Or:
Document how a new user signs up, confirms their email, and reaches the dashboard.
The AI can then use tools like:
browser_snapshotto describe what’s on each pagebrowser_take_screenshotto embed visualsbrowser_console_messagesorbrowser_network_requeststo highlight behind-the-scenes activity
This is especially useful for:
- New team members — generate onboarding guides that are always up to date with the UI
- Developers and testers — create scenario walkthroughs and architecture overviews
- Product or marketing teams — produce customer-facing docs and feature walkthroughs
- Auditors or compliance reviewers — generate flows with screenshots, PDF exports, and logs
And because it’s AI + real browser context, the documentation isn’t theoretical — it’s what actually happens. It’s like pairing your app with an AI that writes the manual as it explores the product.
Development Help (Debugging)
Need to figure out why a flow is broken? Connect an MCP agent, and ask it to:
- Check console logs (
browser_console_messages) - Capture network requests (
browser_network_requests) - Inspect the current UI state via snapshot (
browser_snapshot) - Interactively probe elements (“what’s the accessible name of that button?”)
The AI becomes a debug copilot. It doesn't just help write tests — it helps investigate issues.
Task Automation
Testing is just one use case. Since MCP gives you structured browser control, you can repurpose it for task automation.
For instance:
- Log in to your HR portal and submit a timesheet
- Navigate to internal dashboards and extract key metrics
- Automate repetitive form filling tasks
This makes Playwright MCP a bridge not just between devs and browsers, but also between AI and real-world workflows.
Exotic Use Cases (PDF Archiving, Web Scraping)
Because Playwright MCP gives you tools like browser_snapshot, browser_take_screenshot, browser_pdf_save, and browser_screen_capture, you can build some creative workflows:
- Scrape a dynamic website’s content using semantic structure
- Save full web pages as PDFs for archival or legal records
- Generate visual reports automatically
- ...
These are edge cases, but can be useful in some cases.
Summary
Playwright MCP combines the power of AI agents with the structure of the Model Context Protocol to enable intelligent, automated browser interactions. By exposing Playwright’s functionality through a standardized interface, it allows LLMs to explore, test, and document web applications with high-level, semantic understanding — not just raw DOM data.
Whether you're running functional or exploratory tests, debugging workflows, or generating onboarding docs, Playwright MCP lets AI agents act like thoughtful testers — with access to structured browser feedback via the accessibility tree and a full toolchain exposed dynamically.
It's a new hot thing in the testing world so give it a try and let me know what you think.
I highly recommend you to connect it to your MCP client (e.g. Cursor) and try it out.
Comments
Loading comments...